
|
|
Por favor, use este identificador para citar o enlazar este ítem:
https://repositorio.utn.edu.ec/handle/123456789/16954Registro completo de metadatos
| Campo DC | Valor | Lengua/Idioma |
|---|---|---|
| dc.contributor.advisor | Cuzme Rodríguez, Fabian Geovanny | - |
| dc.contributor.author | Almachi Suriaga, Darwin Oswaldo | - |
| dc.date.accessioned | 2025-03-06T14:42:19Z | - |
| dc.date.available | 2025-03-06T14:42:19Z | - |
| dc.date.created | 2025-02-21 | - |
| dc.date.issued | 2025-03-06 | - |
| dc.identifier.other | 04/TEL/ 050 | es_EC |
| dc.identifier.uri | https://repositorio.utn.edu.ec/handle/123456789/16954 | - |
| dc.description | Evaluar el rendimiento de algoritmos de aprendizaje automático en la detección de spam para optimizar la calidad de la detección de correos electrónicos no deseados en un entorno de comunicación en línea. | es_EC |
| dc.description.abstract | El presente trabajo de tesis se centró en la evaluación del rendimiento de algoritmos de aprendizaje automático para la detección de correos electrónicos de spam, un problema de gran relevancia en el ámbito de la seguridad informática y la gestión de comunicaciones digitales. Para ello, se seleccionaron tres algoritmos ampliamente utilizados en este campo: Naive Bayes, K-Nearest-Neighbor (KNN) y Decision Tree. La investigación inició con la recopilación de un conjunto de datos representativo, asegurando una diversidad de ejemplos que reflejaran casos reales de correos clasificados como spam y no spam. Posteriormente, se llevó a cabo la implementación de los algoritmos, incluyendo su configuración inicial y ajustes específicos para maximizar su rendimiento. Como parte de este proceso, se optimizaron los parámetros de cada modelo con el fin de garantizar que operaran bajo condiciones ideales y se adaptaran a las características del conjunto de datos empleado. El análisis comparativo de los algoritmos se realizó mediante métricas estándar de evaluación, como precisión, recall, F1-score y el área bajo la curva ROC (AUC). Naive Bayes obtuvo una precisión del 97.17%, un recall de 0.686 y un F1-Score de 0.804, mostrando un buen equilibrio. KNN alcanzó una precisión del 100%, pero con un recall de solo 0.293 y un F1-Score de 0.453, lo que limitó su efectividad en la detección de spam. Decision Tree logró una precisión del 87.91%, un recall de 0.64 y un F1-Score de 0.74, ofreciendo un rendimiento intermedio. Estos resultados permitieron identificar fortalezas y debilidades de cada modelo y formular recomendaciones para mejorar los sistemas de filtrado de correos. | es_EC |
| dc.language.iso | spa | es_EC |
| dc.rights | openAccess | es_EC |
| dc.rights | Atribución-NoComercial-CompartirIgual 3.0 Ecuador | * |
| dc.rights.uri | http://creativecommons.org/licenses/by-nc-sa/3.0/ec/ | * |
| dc.subject | EVALUACIÓN | es_EC |
| dc.subject | ALGORITMOS | es_EC |
| dc.subject | APRENDIZAJE | es_EC |
| dc.subject | SPAM | es_EC |
| dc.title | Evaluación de rendimiento de algoritmos de aprendizaje automático en la detección de Spam | es_EC |
| dc.type | bachelorThesis | es_EC |
| dc.description.degree | Ingeniería | es_EC |
| dc.contributor.deparment | Telecomunicaciones | es_EC |
| dc.coverage | Ibarra, Ecuador | es_EC |
| dc.identifier.mfn | 0000044058 | es_EC |
| Aparece en las colecciones: | Telecomunicaciones | |
Ficheros en este ítem:
| Fichero | Descripción | Tamaño | Formato | |
|---|---|---|---|---|
| 04 TEL 050 LOGO.png | LOGO | 191.94 kB | image/png | 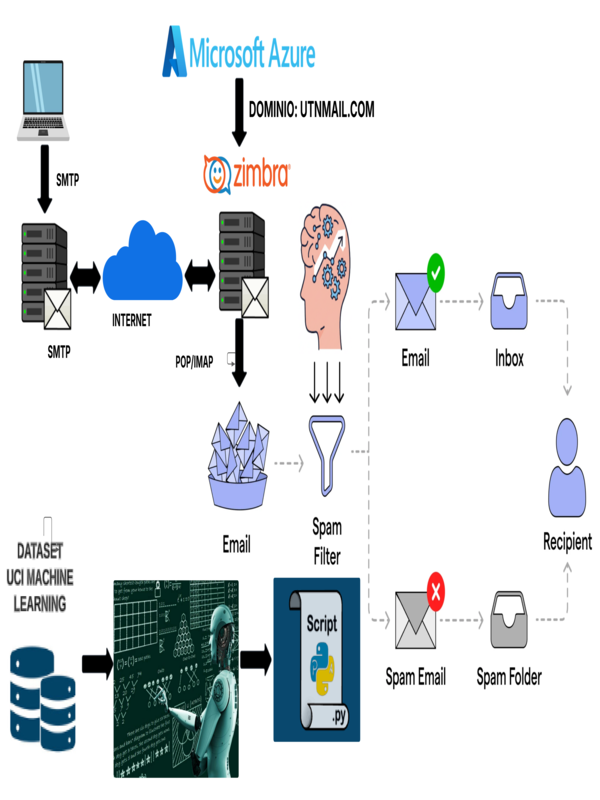 Visualizar/Abrir |
| 04 TEL 050 TRABAJO DE GRADO.pdf | TRABAJO DE GRADO | 4.93 MB | Adobe PDF |  Visualizar/Abrir |
Este ítem está protegido por copyright original |
Este ítem está sujeto a una licencia Creative Commons Licencia Creative Commons

